tl;dr
The face detector used in face recognition example is based on HOG feature extraction.
note
Please refer to "dlib/examples/face_detection_ex.cpp" and "dlib/image_processing/frontal_face_detector.h".
Face Detection based on HOG
note
Refer to the blog Make your own object detector!
Model Training
The code is here.
Fast!
- Only 6 seconds to train on the
dlib/examples/facesdataset! - 3 minutes on 3000 images from LFW dataset!
The example above enable us to visualize the learned HOG detector.

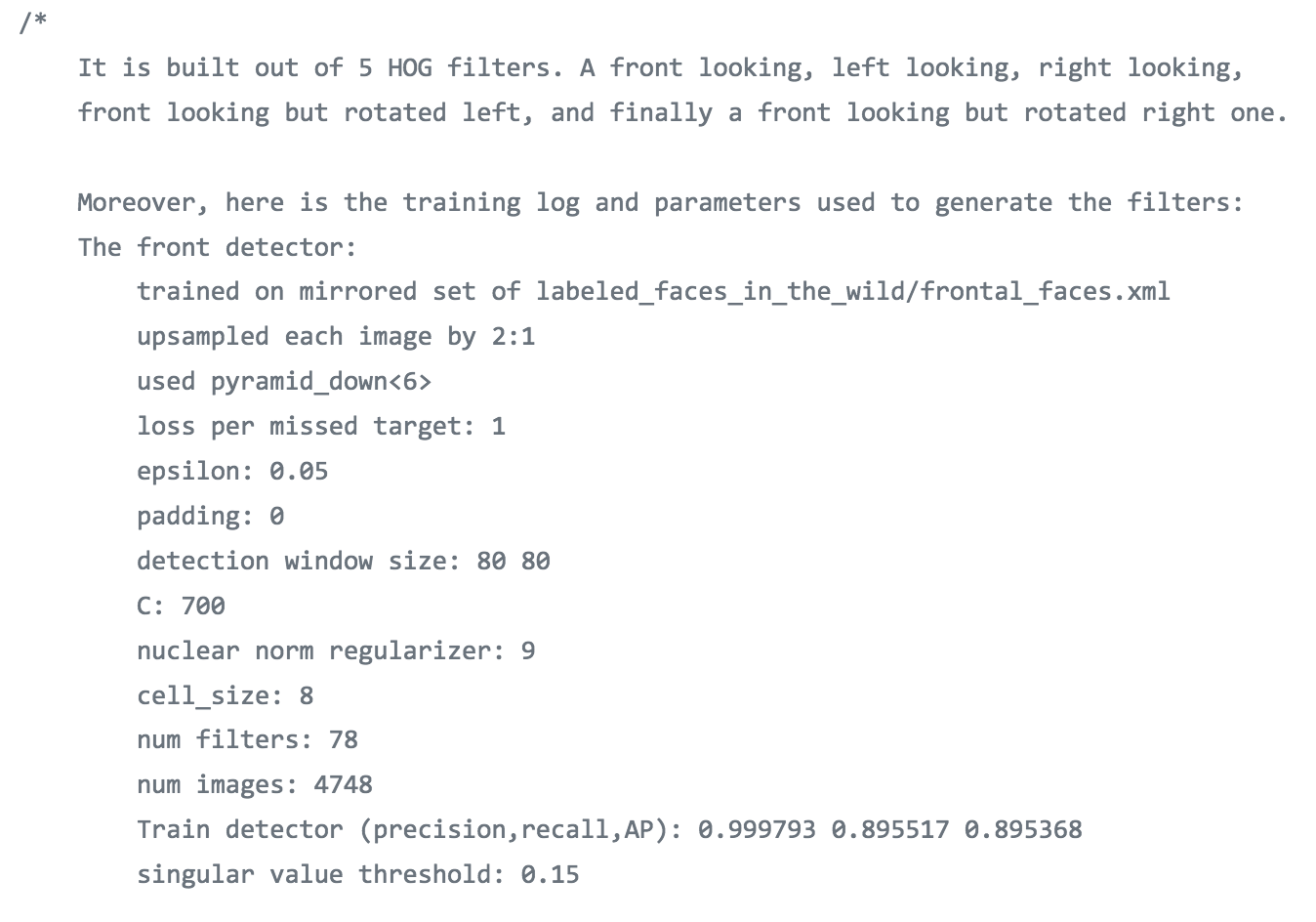
Training Log
Information comes from dlib/dlib/image_processing/frontal_face_detector.h.
Detector Implementation
For faster execution, enable SSE2 instructions. Information comes from dlib/examples/face_detection_ex.cpp.
Face Detection Using DNN
note
These notes are summary of Easily Create High Quality Object Detectors with Deep Learning.
Algorithm (loss function)
The object detecion task was achieved by implementing the max-margin object-detection algorithm (MMOD).
note
D.King actually has a paper about this algorithmMax-Margin Object Detection.
Advantages over HOG Feature Extraction
Previously, the MMOD implementation in dlib used HOG feature extraction followed by a single linear filter. This means the detector is incapable of learning to detect objects that exhibit complex pose variation or have a lot of other variability in how they appear.
Extract Features with CNN
dlib's state of the art face detection is to train a convolutional neural network using MMOD loss function.
note
Please see the tutorial showing how to train a CNN using MMOD loss function in "dlib/examples/dnn_mmod_ex.cpp".
Things Worth Mentioning
Very Few Training Data
4 training images.
Reasonably Fast for a CNN
- On CPU, 370ms to process a 640*480 image.
- On NVIDIA Titan X (Maxwell), it takes 45ms to process an image when mini-batch is 1, while 18ms per image when using a larger mini-batch.
note
If we run the CNN on GPU then it's about the same speed as HOG (which only runs on CPU).
Benchmark
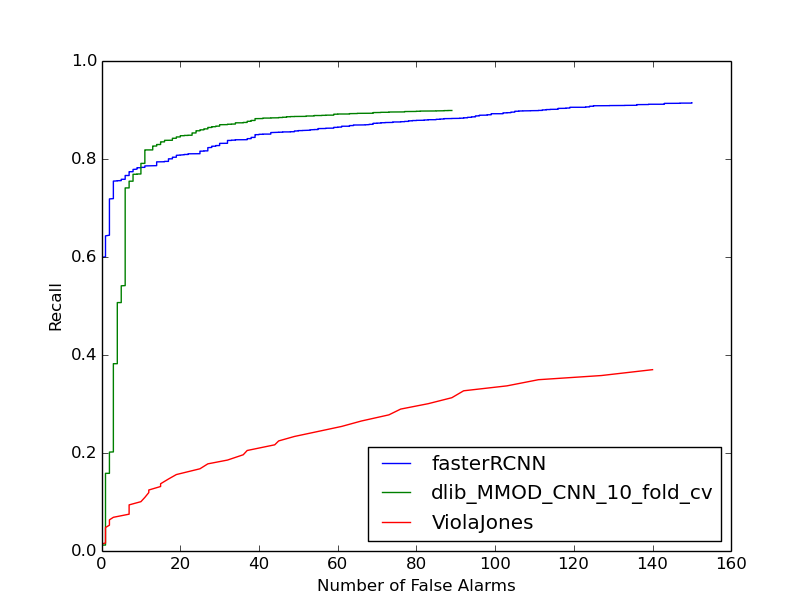
Description of the Plot
The
Xaxis is the number of false alarms produced over the entire 2,845 image dataset. TheYaxis is recall, i.e. the fraction of faces found by the detector.The green curve is the new dlib detector which uses only 4,600 faces to train on.
The blue curve is the state-of-art from
Faster-RCNN. The model was trained with 159,424 faces, and get worse results on FDDB than the dlib detector (with way less training images).
note
Run your own images using "dlib/examples/dnn_mmod_face_detection_ex.cpp".
Way Better Performance than HOG
While the HOG detector does an excellent job on easy faces looking at the camera, we can see that CNN is way better at handling not just the easy cases but all faces in general.
