Reference
Fact: The vast majority of production systems are closed-domain, retrieval-based.
Retrieval-based Question Answering Systems
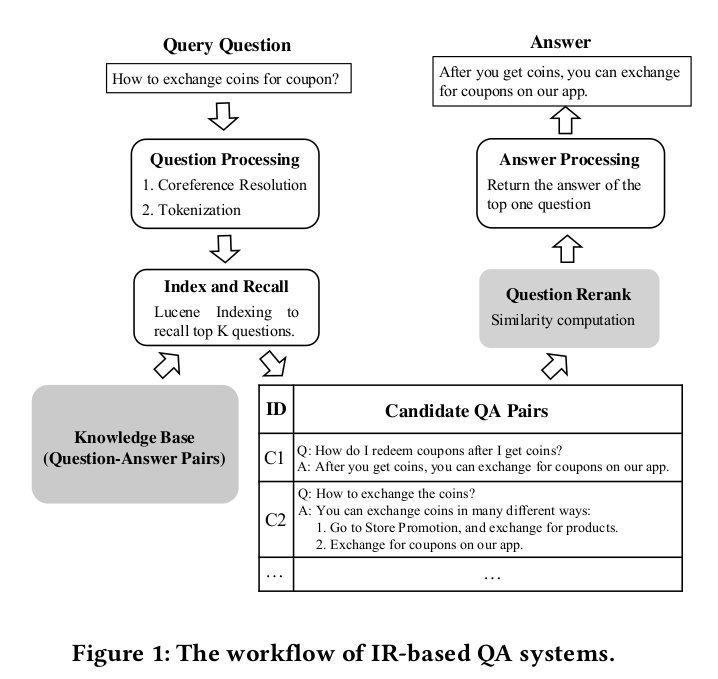
Preprocessing Input / Input Resolution 问句理解
词语层面: 命名实体识别(Named Entity Recognition), 术语识别(Term Extraction), 词汇化答案类型词识别(Lexical Answer Type Recognition), 实体消岐(Entity Disambiguation), 关键词权重计算(Keyword Weight Estimation), 答案集中词识别(Focused Word Detection)...
句法层面: 词与词之间,短语与短语之间的句法关系,分析句子句法结构。最终解析成可计算,结构化的逻辑表达形式。
Each sentence is chunked and broken into separate message objects for the bot to interpret.
Message Object
This is where all the input is cleaned, normalized, parsed and analyzed. The system keeps several representations of the input for various sub-systems.
INPUT: My name is Bill.
Then break it down into individual words...
words: ['My', 'name', 'is', 'Bill']
Then tag each word with a Parts-of-Speech tagger...
tagger_words:[
['My', 'PRP$'], // Personal pronoun
['name', 'NN'], // Noun
['is', VBZ], // Verb present
['Bill', 'NNP'] // Proper noun
]
Pull out individual parts and keep them separate as...
nouns: ['name', 'bill']
verbs: ['be']
pronouns: ['my']
adjectives: []
adverbs: []
Extract Named Entities, dates and numbers...
names: ['Bill']
date: null
numbers: []
Check if it is a question, and its type
is_question: false
Sentiment analysis of the message, possitive / negative / neutral...
sentiment: 0 // neutral
Preprocessing techniques: parser, parts-of-speech tagging (POS), named entity recognition (NER), intent / sentiment analysis...
note
目前已有较好的,开源的,工具完成中文分词,POS标注,命名实体识别。意图识别及语义分析模型需要自己“训练”。
Input Normalizer
- Stemming and Lemmatization
- Convert British and Canadian spelled words to US English, fix mis-spelled words, expand abbreviations and contractrions.
note
对于中文,有繁简转换的问题。其他部分对中文相对容易,甚至可省略。
Question Types
If input contains a question.
Classify question type based on over many sub-classifications of how the question should be answered.
Here is a reference list.
Examples
- CH: Choice or alternative Question.
Is the water hot or cold? - WH:
who, what, where, when, why - YN: Yes / No Question.
Do you have a pencil? - TG: Tag Question. They are not really questions.
It is beautiful, isn't it?
INPUT: What time did the train leave London?
is_question: True
q_type: 'NUM:date'
q_subtype: 'WH'
Sentiment Analysis 语义分析
Idea
Label intent and entities within a sentence, then train a model based on such dataset.
标注出句子中的意图(intent)和实体(entity),再通过训练调整问答模型。
Example
INPUT: 我要买一瓶红酒
意图:"购买物品"
实体:"红酒", "一瓶"
Approaches
We don't really know. It might be neural network based estimation, Latent Dirichlet Allocation, knowledge graph, or something else. Or it might be a complex rule system.
Semantic Graph -- One of Easy ones 语义图
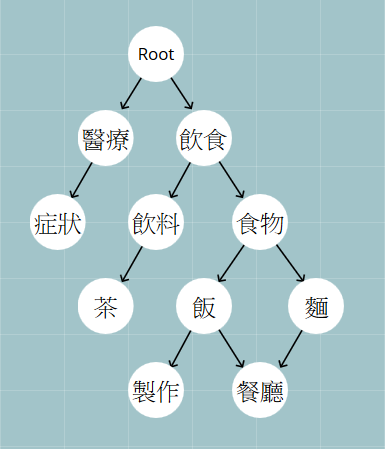
Figure credit to http://zake7749.github.io/2016/12/17/how-to-develop-chatbot/
Example
INPUT: 这附近有什么好吃的
(意图是)饮食 -> (是想吃)食物 -> (想吃)饭 -> (附近跟地点有关,所以想找)餐厅
基于语义图,定义两种运算行为:
- 找准进入点。从”好吃“对应到了进入点”饮食“。
- 词义解析。找出系统内与”好吃“最相关的概念,结果是”饭“。
note 当一个词完成了词义解析后,该词就算处理完了,不会再次被语义图视为进入点。 符合多论对话的需求。