Idea
Motivation
The depth of representations is of central importance for many visual recognition tasks, i.e. we need to go deeper.
Challenge
Deep neural nets are extremely difficult to optimize.
Possible Reason:
We conjecture that the deep plain nets may have exponentially low convergence rates. Experiments reveal that degradation problem cannot be feasibly addressed by simply using more iterations.
[ Degradation ]
With stacking more layers, training error increases.
Hypothesis
It is easier to optimize the residual mapping than to optimize the original, unreferenced mapping.
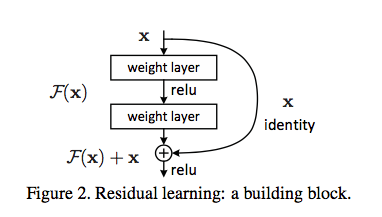
Approach
To explicitly reformulate the layers as learning residual functions with reference to the layer inputs, rather than learning unreferenced functions.
Why ResNet works
By such reformulation, identity mapping become much easier to learn than previous.
Things Worth Mentioning
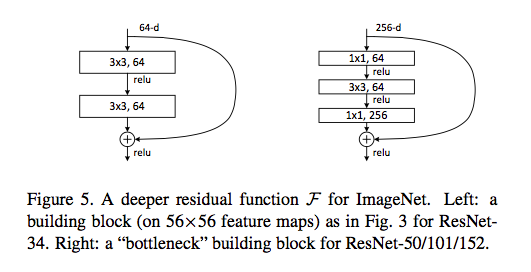
Deeper Bottleneck Architectures
Bottleneck design is due to practical considerations, that is non-bottleneck can gain accuracy from increased depth but not as economical as bottleneck block.
[ Thought ]
Degradation problem is caused by difficulty in learning identity mapping, will a more better optimizer solve the problem?
Further Reading
- Vanishing gradient problem
- Initialization methods mentioned in the paper
- Strong regularization:
maxoutanddropout Network in Network- 1x1 convolutional layer- Why BatchNorm works