Notes taken from paper A Few Useful Things to Know about Machine Learning, Pedro Domingos.
Learning = Representation + Evaluation + Optimization
Representation
A classifier must be represented in some formal language that the computer can handle.
Often, the set of classifiers are called hypothesis space.
Evaluation
Evaluation function / objective function is needed to distinguish good classifiers from bad ones.
Optimization
The method to search among the classifiers for the highest-scoring one.
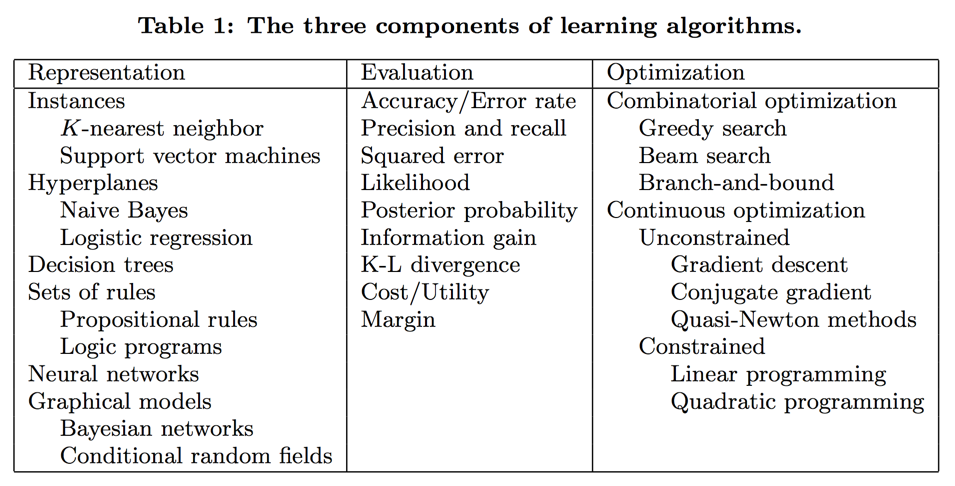
Note Hyperplane-based methods form a linear combination of the features per class and predict the class with the highest-valued combination.
It's Generalization that Counts
The objective function is only a proxy for the true goal, we may not need to fully optimize it.
Data Alone is not Enough
One of the key criteria for choosing a representation is which kinds of knowledge are easily expressed in it.
Overfitting Has Many Faces
Bias: is a learner's tendency to consistently learn the same wrong thing.
Variance: is the tendency to learn random things irrespective of the real signal.
Note Strong false assumptions can be better than weak true ones, because a learner with the latter needs more data to avoid overfitting.
Note Adding regularization term to evaluation function is to penalize classifiers with more structure, thereby favoring smaller ones with less room to overfit.
Intuition Fails in High Dimensions
curse of dimensionality
blessing of non-uniformity: In most applications examples are not spread uniformly throughout the instance space, but are concentrated on or near a lower-dimensional manifold.
Theoretical Guarantees are not What They Seem
The main role of theoretical guarantees in machine learning is not as a criterion for practical decisions, but as a source of understanding and driving force for algorithm design.
Learn Many Models not Just One
Bagging: generate random variations of the training set by resampling, learn a classifier on each and combine the results by voting.
Bagging works because it greatly reduces variance while only slightly increasing bias.
Boosting: training examples have weights, and these are varied so that each new classifier focuses on the examples the previous ones tended to get wrong.
Boosting works by reducing bias, i.e. more powerful predictive capability.
Stacking: the outputs of individual classifiers become the inputs of a "high-level" learner that figures out how best to combine them.