VGG Dataset Statistics
Train dataset
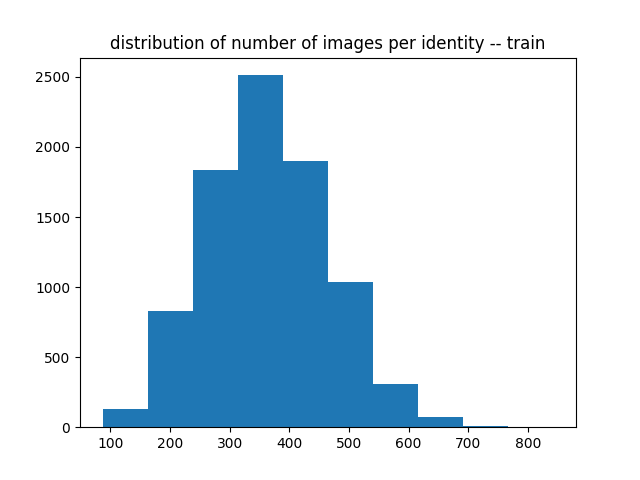
VGG train
| statistic | value |
|---|---|
| Number of Identity | 8,631 |
| Number of Total Images | 3,141,890 |
| Min of # Images / ID | 87 |
| Max of # Images / ID | 843 |
| Median of # Images / ID | 359 |
VGG test
| statistic | value |
|---|---|
| Number of Identity | 500 |
| Number of Total Images | 163,396 |
| Min of # Images / ID | 98 |
| Max of # Images / ID | 761 |
| Median of # Images / ID | 325 |
Model Training
192.168.2.174:/media/harddrive1/SGAO/cstor-projects/face-recognition-pytorch/
192.168.2.174:/media/harddrive1/SGAO/cstor-projects/face-recognition-dlib/dataset/vgg-dataset
Training 1-- Classification Problem (04/16/2018)
Mode: Classification problem, (8,361 categories) Data Loading: PyTorch built-in scheme mini-batch size: 1,792
Training 2 -- Classification Problem (04/18/2018)
Mode: Classification problem, (8,361 categories) Data Loading: Custom scheme made by SGAO mini-batch size:
DataSet Object by SGAO
192.168.2.174:/media/harddrive1/SGAO/cstor-projects/face-recognition-pytorch/dataloader_sgao/datasets_dlib.py
Dlib style: mini-batch size = (num1, num2), where num1 indicates the number of identities and num2 indicates the number of images of each of these identities.
Implementation:
__len__method: defined as2 x num_total_id / num1__getitem__method: returns[Tensor (size=num1 x C x H x W), Tensor (size=num2)]
Model Object by SGAO
192.168.2.174:/media/harddrive1/SGAO/cstor-projects/face-recognition-pytorch/models_sgao/net_dlib.py
Dlib Style: 29-layer ResNet with reduced number of kernels of each convolutional layer.
Loss Object by SGAO (04/18/2018)
192.168.2.174:/media/harddrive1/SGAO/cstor-projects/face-recognition-pytorch/loss_sgao/loss_sgao.py
Pair-wise hinge loss with hypterparameters which are distance and margin.
Performs hard negative mining.
TRICK: access model attributes wrapper by nn.DataParallel (PyTorch)
According to discussion:
model.module.attribute
Modify accuracy metric (04/19/2018)
if label[i] == label[j]:
if dist(i, j) < threshold:
num_right += 1
else:
num_wrong += 1
else:
if dist(i, j) >= threshold:
num_right += 1
else:
num_wrong += 1
accuracy = 100.0 * num_right / (num_right + num_wrong)
UPDATE on accuracy metric (04/20/2018)
Example,
Given: batch_size = (36, 48), then
num_same_pair = 36 x 48 x 47 / 2 = 40,608
num_diff_pair = (36 x 48) x (36 x 48) / 2 - num_same_pair = 1,451,520
When `num_diff_pair` are all correct while `num_same_pair` are all wrong,
accuracy = 1,451,520 / (40,608 + 1,451,520) = 0.972785
According to the above example, we observe the imbalance of "same identity pairs" and "different identity pairs" causes the accuracy metric to mean less.
Two approaches to remedy
- Modify the validation mini-batch size for more balanced data
- Modify the accuracy subroutine, using weighted accuracy