Numerical Computing
Poor Conditioning
Conditioning refers to how rapidly a function changes with respect to small changes in its inputs.
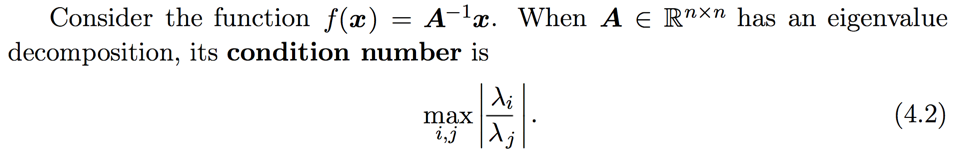
Note
When this number is large, matrix inversion is particularly sensitive to error in the input.
Gradient-Based Optimization
Terms
- gradient descent
- first derivative being zero
- critical points / stationary points
- local minimum
- local maximum
- saddle point
- global minimum
Jacobian and Hessian Matrices
Jacobian


Note
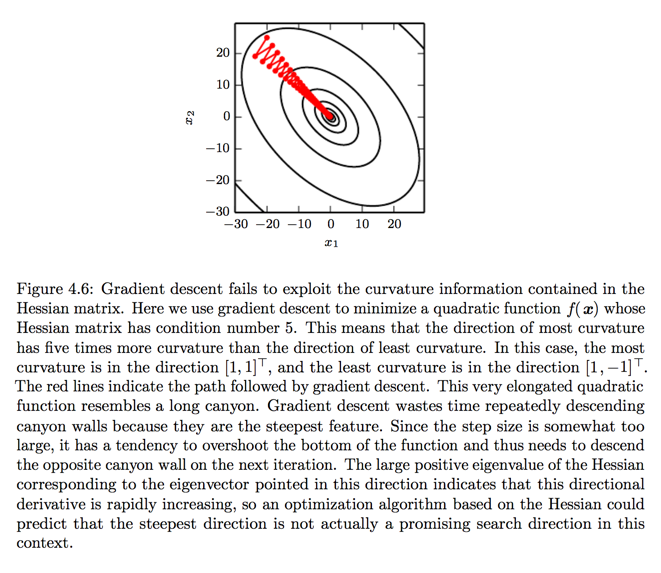
- Eigenvalues of Hessian matrices determine the scale of learning rate.
- In multiple dimensions, there is a different second derivative for each direction at a single point.
- The "condition number" of the Hessian at this point measures how much the second derivatives differ from each other.
- When the "condition number" is poor, gradient descent performs poorly.
Second Derivative as Curvature
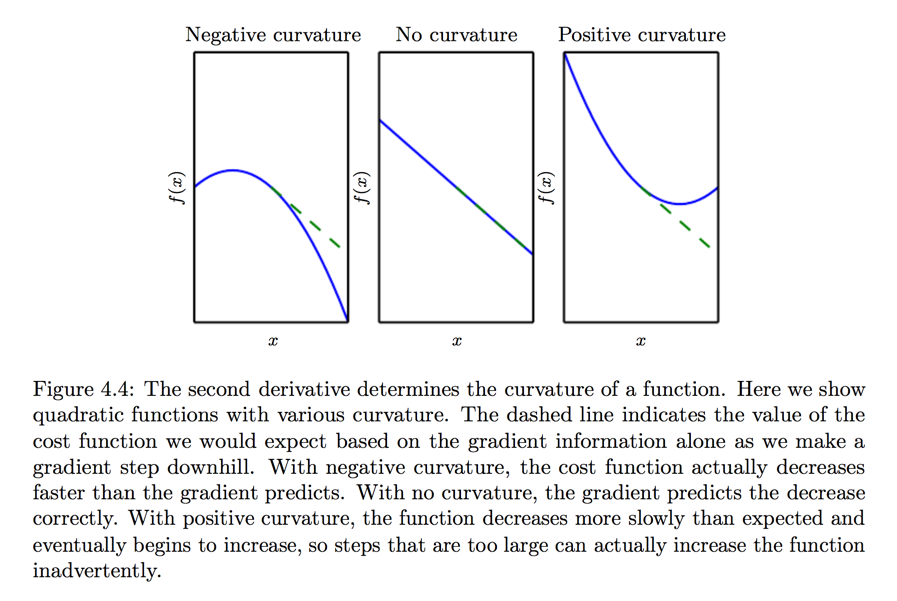
Note
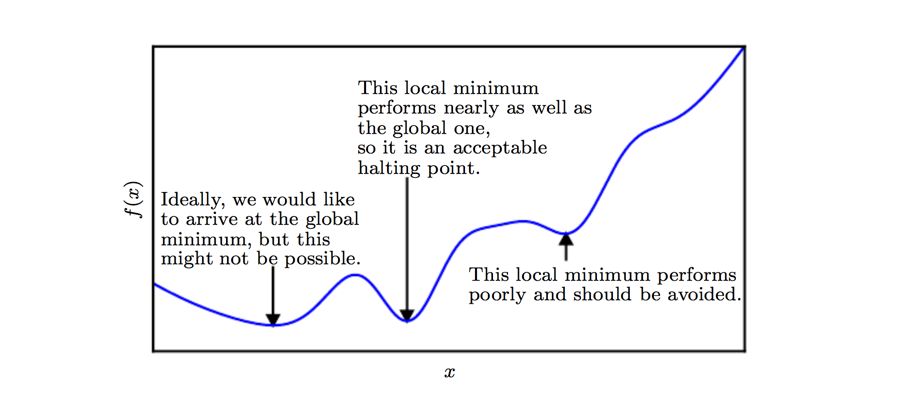
The second derivative can determine whether a critical point is a saddle point or local minimum.
Saddle point containing both positive and negative curvatures
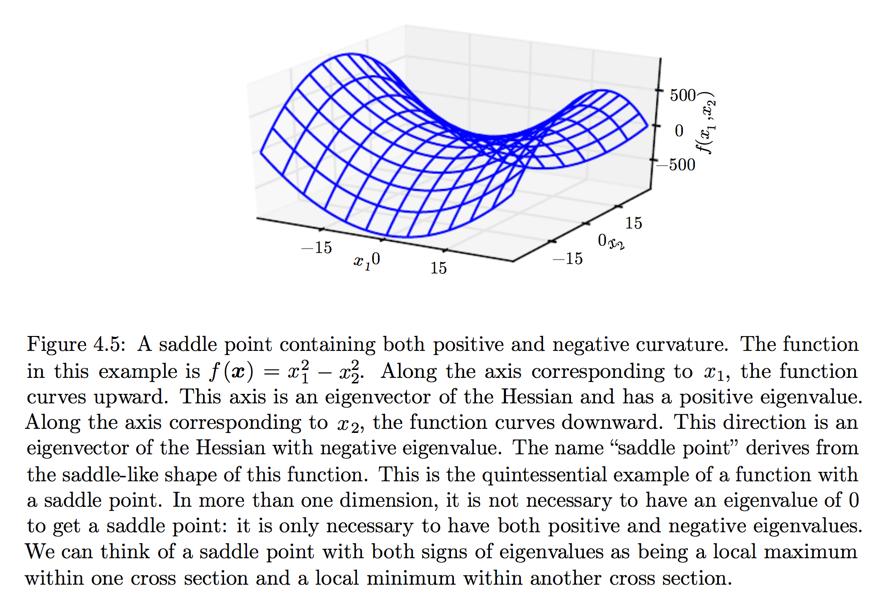
First-Order / Second-Order Optimization
Optimization algorithms that use only the gradient, such as gradient descent are called first-order optimization algorithms.
Optimization algorithms that use Hessian matrix such as Newton's method are called second-order optimization algorithms.
Lipschitz Continuous & Convex Optimization
Deep learning algorithms lack guarantees because the family of functions used in deep learning is quite complicated.
Note
In many other fields, the dominant approach to optimization is to design optimization algorithms for a limited family of functions.
Lipschitz continuous

Convex optimization Convex optimization algorithms are able to provide many more guarantees by making stronger restrictions, i.e. only applicable to convex functions whose Hessian is positive semidefinite everywhere.