Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Note
By staring at the title, batch normalization is a technique to accelerate training.
Another Note
Training speed is measured in two ways: (1) iteration steps; (2) computation time. This paper is concerned with the former.
Example
Match the performance of a ImageNet Classifier using only 7% of the training steps.
Motivation
Why using mini-batch
First consider the advantages of using mini-batches rather than a single example. The reason is two-folds:
- First, the gradient of the loss over a mini-batch as an estimate of the gradient over the training set, whose quality improves as the batch size increases;
- Second, computation over a batch can be much more efficient than
mcomputations for individual examples, due to the parallelism afforded by modern computing platforms.
Avoid Covariate Shift
[ Covariate Shift ]
A learning system experience covariate shift when its input distribution changes. To be specific, we refer to the change in distributions of internal nodes of a deep network in the course of training as Internal Covariate Shift.
It is advantageous for the distribution of inputs of network nodes to remain fixed over time. By fixing input distribution, problems such as saturation, vanishing / exploding gradients can be avoid.
Effects of Batch Normalization
- Use ReLU, saturation and whatever activations functions we like;
- Initialize network parameters without so much care;
- Use higher learning rates thus accelerate training;
- Regularizes the network, no need for
Dropout; WHY dropout specifically?
Details of Batch Normalization
First normalize each scalar feature independently by making it have the mean of 0 and the variance of 1.
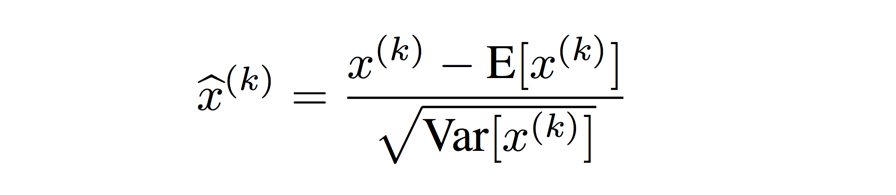
Network Capacity Consideration
Note that simply normalizing each input of a layer may change what the layer can represent, i.e. harm its representational power / network capacity.
To address this, we make sure that the transformation inserted in the network can represent the identity transform.
Note
Familiar? Make identity mapping easy to learn. Think about ResNet block.
To Not Harm Network Capacity
Introduce for each activation, a pair of parameters gamma and beta:
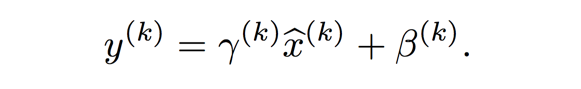
Each normalized activation can be viewed as an input to a sub-network composed of the above linear transform, followed by the other processing done by the original network.
Implementation

Inference with Batch Normalized Networks
During inference, we use statistics -- mean and variance of the population, rather than mini-batch.
Batch-Normalized Convolutional Networks
We want different elements of the same feature map at different locations are normalized in the same way.
So for a mini-batch of size m and feature maps of size p x q, we use the effective mini-batch of size m x pq. And we learn pair of gamma and beta per feature map.