Regularization for Deep Learning
Regularization is a collection of strategies to reduce text error. Developing more effective regularization strategies has been one of the major research efforts in the field.
Regularization strategies include:
- Put extra constraints on a machine learning model
- adding restrictions on parameter values;
- adding extra terms in the objective function, i.e. a soft constraint on the parameter values;
- Design constraints and penalties to encode specific kinds of prior knowledge, for example, preference for a simpler model in order to promote generalization
- Ensemble methods, combine multiple hypotheses that explain the training data
Idea
Regularization of an estimator works by trading increased bias for reduced variance, i.e. Bias & Variance tradeoff.
Previous Experience
The best fitting model (in the sense of minimizing generalization error) is a large model that has been regularized appropriately.
Parameter Norm Penalties
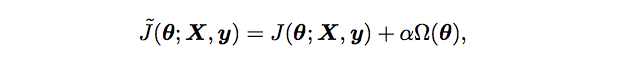
Note
For neural networks, we typically only penalize the weights of the affine transformation and leaves the biases unregularized.
L2 Parameter Regularization
L2 parameter norm penalty is commonly known as weight decay.
What happens in a single step

Explanation
The addition of the weight decay term has modified the learning rule to multiplicatively shrink the weight vector by a constant factor on each step just before performing the usual gradient update.
The Effect L2 Regularization
- Directions along which the parameters contribute significantly to reducing the objective function are preserved relatively intact;
- Components of the weight vector corresponding to unimportant directions are decayed away through the use of regularization throughout training.
Note
Review how a real, symmetric matrix can be decomposed into a diagonal matrix and an orthonormal basis of eigenvectors! Fuck linear algebra!
L1 Regularization
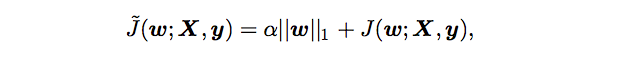
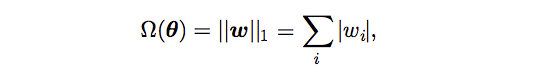
that is, the sum of absolute values of the individual parameters.
Corresponding gradient:
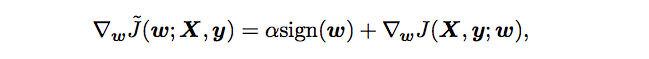
Difference from L2 regularization:
The regularization contribution to the gradient no longer scales linearly with each weight, instead it is a constant factor with a sign equal to sign of that weight.
Specifically, for each weight,

L1 Regularization Analysis
- In comparison to
L2regularization,L1results in a more sparse solution, i.e. some parameters have an optimal value of zero. - The sparsity property has been used extensively as a feature selection mechanism.
Dataset Augmentation
This technique is particularly effective for object recognition problem.
Operations like translating images a few pixels has been proven to be useful even if translation invariant is introduced by convolution and pooling.
Injecting noise in the input
One way to improve robustness of neural networks is to train them with random noise applied to their inputs.
Dropout can be seen as a process of constructing new inputs by multiplying by noise.
Note
It is important to take the effect of dataset augmentation into account when comparing machine learning benchmark results.
Semi-Supervised Learning
In the context of deep learning, semi-supervised learning usually refers to learning a representation h = f(x).
Multi-task Learning
Example: Faster-RCNN!
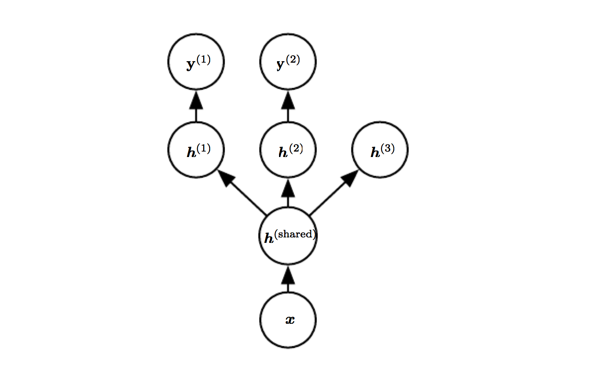
The model can generally be divided into two kinds of parts and associated parameters:
- Task-specific parameters which are the upper layers of the neural network.
- Generic parameters, shared across all the tasks which are the lower layers of the neural network.
The underlying prior belief: among the factors that explain the variations observed in the data associated with the different tasks, some are shared across two or more tasks.