References
Taxonomy of Question-answering Models 问答系统模型分类
Based on the technology used, QA systems can be generalized into following models. 根据所用的技术,问答系统可分类为。
- Rule-based Model 样板式模型
- Retrieval-based Model 检索式模型
- Generative model 生成式模型
Rule-based Model 样板式模型
For example,
if 'weather' in user.query:
chatbot.say('What a lovely weather today!')
Rule Format 规则格式
Use json to store the rules.
{
"domain": "代表这个规则的抽象概念",
"response": [
"对应到规则后",
"机器人所给予的回复",
"机器人会随机抽取一条 response"
],
"concepts": [
"该规则的可能表示方式"
],
"children": ["该规则的子规则", "如购买 -> 购买食物、衣服"]
}
Example
{
"domain": "购买",
"response": [
"正在将您导向购买模组",
],
"concepts": [
"购买", "购物", "订购"
],
"children": [
"购买生活用品",
"购买家电",
"购买食物",
"购买饮料",
...
]
}
Retrieval-based Model 检索式模型
question_answer_pair = [(q1, a1), (q2, a2), ..., (qn, an)]
Idea
Compare the asked question to Questions, then calculate similarity, propose the one which has the most resemblance, e.g. qk
Then fetch answer ak.
note
These systems do not generate any new text, they just pick a response from a fixed set.
Approach
The idea is to map question qk to a topic (主题).
training set(text, label) 训练集(文本,主题)
('勒布朗詹姆斯今年夏天会离开骑士前往湾区吗?', '体育')
('熊出没能得到今年奥斯卡最佳动画片奖吗?', '文娱')
...
例如, 当提问说“今天雷霆队的比分是多少”,我们会知道问题的意图是问体育赛事。此外,这个问句里面有“雷霆队”,“今天”,“比分”这三个特征。
Classification --> Machine Learning
Feature Extraction --> Named Entity Recognition (NER)
用机器学习解决主题分类问题,用命名实体识别提取特征。
Pros and Cons
Due to the repository of handcrafted responses,
Pros
- retrieval-based methods do not make grammatical mistaks
Cons
- they man be unable to handle unseen cases
- these models cannot refer back to contextual entity information like names mentioned earlier in the conversation
note
The following model, generative models are "smarter". They can refer back to entities in the input. However, these models are hard to train, and are likely to make grammatical mistakes (especially on longer sentences). And typically require huge amounts of training data.
Generative Model 生成式模型
Use cases may not be limited to a specific domain, but more human like.
Illustration of Basic Idea

Conversation Types
Short-text Conversations
The goal is to create a single response to a single input. i.e. single turn
Long Conversations
Go through multiple turns and need to keep track of what has been said.
note
Customer support conversations are typically long conversational threads with multiple questions.
Open Domain v.s. Closed Domain
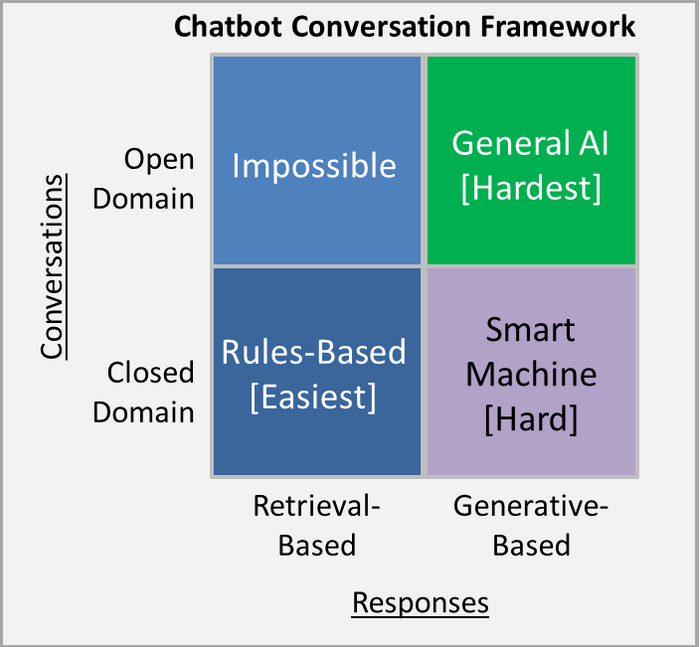
Open Domain
Conversations on social media sites like Twitter, Reddit, Weibo etc.
Closed Domain (The one we are interested in)
Technical Customer Support & Shopping Assistants
根据数据源分类
- 检索式问答
- 社区问答
- 知识库问答
检索式问答
问题分析 --> 篇章检索 --> 答案抽取
根据“抽取”方法的不同,又可以分为基于模式匹配和基于统计文本信息抽取的问答方法。
- 基于模式匹配的方法
判断问句类型。
- 基于统计文本信息抽取
Logic Form, 词汇链
社区问答
User-Generated Content, UGC 基于用户生成内容。WEB2.0
Yahoo 百度知道 Quora...
知识库问答
知识图谱,知识库, knowledge graph (实体,关系,实体)